面试常考的一个问题,可以每个节点都可以深入探讨,很考验面试者的技术储备。接下来我们依次解析每个阶段的处理过程。
URL 解析
URL 会被浏览器解析为可用的字段,主要包括网络协议、网络地址、资源路径。
- 网络协议:从计算机获取资源的方式,常见的是HTTP,HTTPS,FTP等
- 网络地址:域名或者IP地址,主要执行请求的地址信息。也包括端口信息,若没有端口信息,https 默认 443,http 默认 80
- 资源路径:服务器上需要获取资源的具体路径
url:http://www.test.com:8080/page/index.html?id=1&name=w#name
- 协议部分: 该URL的协议部分为“http:”,这代表网页使用的是HTTP协议。在Internet中可以使用多种协议,如HTTP,FTP等等本例中使用的是HTTP协议。在"HTTP"后面的“//”为分隔符;
- 域名部分: 该URL的域名部分为“www.test.com”。一个URL中,也可以使用IP地址作为域名使用
- 端口部分: 跟在域名后面的是端口,域名和端口之间使用“:”作为分隔符。端口不是一个URL必须的部分,如果省略端口部分,将采用默认端口(HTTP协议默认端口是80,HTTPS协议默认端口是443);
- 虚拟目录部分: 从域名后的第一个“/”开始到最后一个“/”为止,是虚拟目录部分。虚拟目录也不是一个URL必须的部分。本例中的虚拟目录是“/page/”;
- 文件名部分: 从域名后的最后一个“/”开始到“?”为止,是文件名部分,如果没有“?”,则是从域名后的最后一个“/”开始到“#”为止,是文件部分,如果没有“?”和“#”,那么从域名后的最后一个“/”开始到结束,都是文件名部分。本例中的文件名是“index.html”。文件名部分也不是一个URL必须的部分,如果省略该部分,则使用默认的文件名;
- 锚部分: 从“#”开始到最后,都是锚部分。本例中的锚部分是“name”。锚部分也不是一个URL必须的部分;
- 参数部分: 从“?”开始到“#”为止之间的部分为参数部分,又称搜索部分、查询部分。本例中的参数部分为“id=1&name=w”。参数可以允许有多个参数,参数与参数之间用“&”作为分隔符。
缓存判断
浏览器会判断所请求的资源是否在缓存里,如果请求的资源在缓存里且没有失效,那么就直接使用,否则向服务器发起新的请求。
DNS 解析
若网络地址为 ip,则跳过本阶段,若为域名,则进行 DNS 解析。
每个主机名 (hostname) 在页面加载时通常只需要进行一次 DNS 查询。但是,对于页面指向的不同的主机名,则需要多次 DNS 查询。如果字体(font)、图像(image)、脚本(script)、广告(ads)和网站统计(metric)都有不同的主机名,则需要对每一个主机名进行 DNS 查询。
层次化域名空间根域名 在我们输入网址 www.xxxx.com 的时候浏览器实际访问的是 www.xxxx.com. 最后会有一个 '.',这个点就是根域。 顶级域名(一级域名) 网址 www.xxxx.com 中的 .com 就是顶级域名。例如: .cn、.org、.edu 等这些都是顶级域名。 二级域名 网址 www.xxxx.com 中的 xxxx.com 就是二级域名。例如: .com.cn、.net.cn、.edu.cn 等。 三级域名 网址 www.xxxx.com 就是一个三级域名。
DNS 服务器本地域名服务器(LDNS) 每个电脑都预置了本地 DNS 服务器(简称 LDNS),当访问域名的时候就会向本地 DNS服务器发送请求,最终通过权威域名服务器得到答案。 权威域名服务器(权威 DNS) 负责对请求做出权威的回答。 权威域名服务器会有三种返回结果:
- A 记录: 记录着某域名和其 IP 的映射。
- NS 记录: 记录着某域名和负责解析该域名的权威域名服务器。
- CNAME 记录: 记录着某域名及其别名。
当有请求来询问域名,权威域名服务器负责告诉 LDNS 对应 IP(A 记录);如果是需要其他权威域名服务器回答的,则告诉 LDNS 可能知道该域名对应 IP 的权威域名服务器(NS 记录);如果该域名是一个别名类型的就告诉 LDNS CNAME(CNAME 记录),LDNS 再去解析别名。 根域名服务器(根 DNS) 当 LDNS 啥都不知道,没有任何结果的时候(没有任何缓存)就会来问根域名服务器,它可以告诉 LDNS 下一步该去问谁。
查询流程浏览器缓存 => 系统hosts文件 => 本地DNS解析器缓存 => 本地域名服务器 => 根域名服务器 => 主域名服务器 => 下一级域名域名服务器 客户端 => 本地域名服务器(递归查询) 本地域名服务器 => DNS服务器的交互查询是迭代查询
没有缓存时的解析过程 以 www.test.com 为例:
- 在浏览器中输入 www.test.com 后询问本地域名服务器: www.test.com 的 IP 是什么。
- 本地域名服务器不知道其对应 IP,则会询问根域名服务器: .(根域名服务器) 的 IP 是什么。
- 根域名服务器答复: 我也不知道,但是 .com 域名服务器有可能知道,你可以去问问它。
- 本地域名服务器向 .com 域名服务器询问: www.test.com 的 IP 是什么。
- .com 域名服务器答复: 我也不知道,但是 test.com 域名服务器有可能知道,你可以去问问它。
- 本地域名服务器向 test.com 域名服务器询问: www.test.com 的 IP 是什么。
- test.com 域名服务器答复: 对应的 IP 或者 别名为 1.1.1.1。
- 如果本地域名服务器得到的是一个别名,则还需要对别名进行查询。
- 本地域名服务器到 IP 之后本地域名服务器做两件事情:
- 将 IP 返回给浏览器。
- 将 IP 放到缓存中。
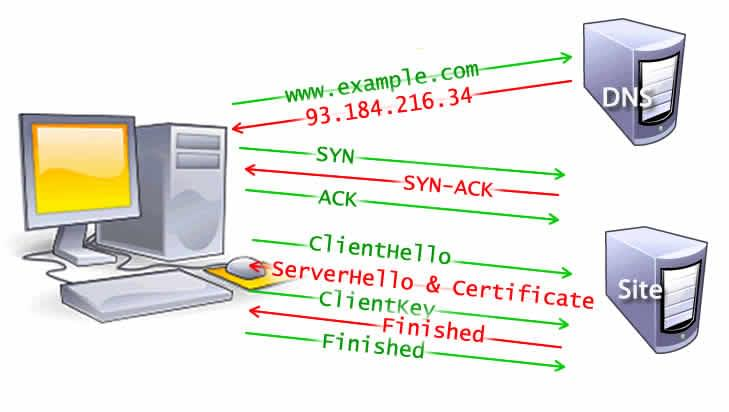
TCP 三次握手
一旦获取到服务器 IP 地址,浏览器就会通过TCP“三次握手”与服务器建立连接。
单词解释
- seq(sequence number): 序列号/顺序号;用来表示 TCP 发起端向接收端发送的字节流,发起端发送数据时对此进行标记。(可以理解为发送自己的数据)
- ack(acknowledgement number): 确认号;只有 ACK 标志位存在时,确认号字段才有效。(可以理解为发送接收到的数据)
- 标志位(flags): 共 6 个,具体含义如下:
- URG: 紧急指针(urgent pointer)有效。
- ACK: 确认号有效。(为了与确认号 ack 区分开,这里采用大写,可以理解为用于确定收到了请求)。
- PSH: 接收方应该尽快将这个报文交给应用层。
- RST: 重置连接。
- SYN: 发起一个新连接。
- FIN: 释放一个连接。 作用
- seq(序号)、ack(确认号): 用于确认数据是否准确,通信是否正常。
- 标志位: 用于确认/更改连接状态。
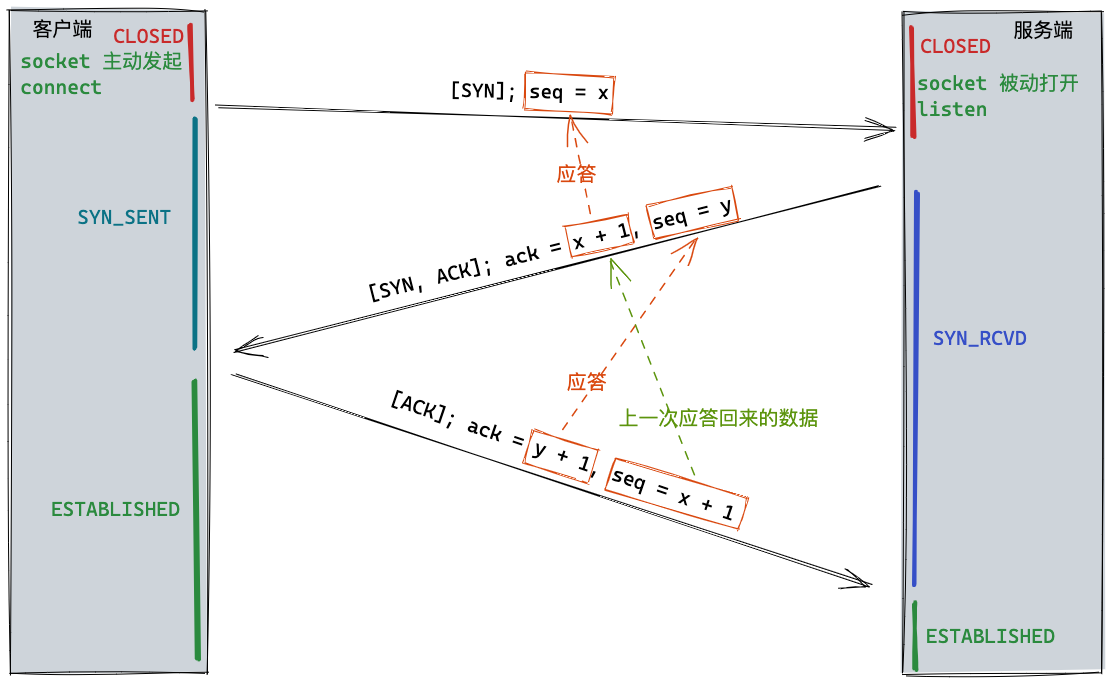
第一次握手
由浏览器发起,询问服务器我可以和你建立连接吗,可以接收到我的数据吗? 客户端发送一个标志位 SYN、序列号 seq = x 的数据包。发送完成后,客户端进入 SYN_SEND 状态(链接发送状态)。
- 标志位 SYN 表示要建立连接。(我可以和你建立连接吗)
- 序列号 seq = x 表示向接收端发送的数据。(可以接收到我的数据吗) 第二次握手
由服务端发起,服务端答应可以建立连接,已收到你的连接请求,能收到我的数据吗?你这数据是这个吗?
服务端发送一个标志位 SYN、标志位 ACK、序列号 seq = y 和 确认号 ack = x + 1 的数据包。发送完成后服务端进入 SYN_RCVD 状态(连接收到状态)。
- 标志位 SYN 表示要建立连接。(可以建立连接)
- 标志位ACK 表示收到了请求。(已收到你的连接请求)
- 序列号 seq = y 表示向接收端发送的数据。(能收到我的数据吗)
- 确认号 ack = x + 1 表示上一次握手发来的序列号 seq 的值 + 1。(你这数据是这个吗) 第三次握手
由客户端发起,客户端应答已收到你的回复,这是我的数据,这是你的数据。我马上就要发送请求了,准备接收吧。
客户端发送一个标志位为 ACK、确认号 ack = y + 1 和序列号 seq = x + 1 的数据包。
- 标志位 ACK 表示收到请求。(已收到你的回复)
- 序列号 seq = x + 1 表示上一次握手发来的 ack 的值。(这是我的数据)
- 确认号 ack = y + 1表示上一次握手发来的序列号 seq 的值 + 1。(这是你的数据)
- 将双方的数据发送用于再次验证核对
需要三次握手的本质 信道传输是不可靠的,但是我们要建立可靠的连接并且发送可靠的数据,也就是数据传输是需要可靠的。在这个时候三次握手是理论上的最小值。三次握手并不是说是 TCP 协议要求的,而是为了满足在不可靠的信道上传输可靠的数据所要求的。
- 使用客户发送的能力,使用服务端的接收能力。
- 使用服务端的发送能力,使用客户端的发送能力。服务端确定客户端的发送能力,确定服务端的接收能力。客户端确定服务端的发送接收能力和客户端的发送接收能力。
- 服务端确定客户端的发送接收能力
HTTPS 的 TLS 四次握手
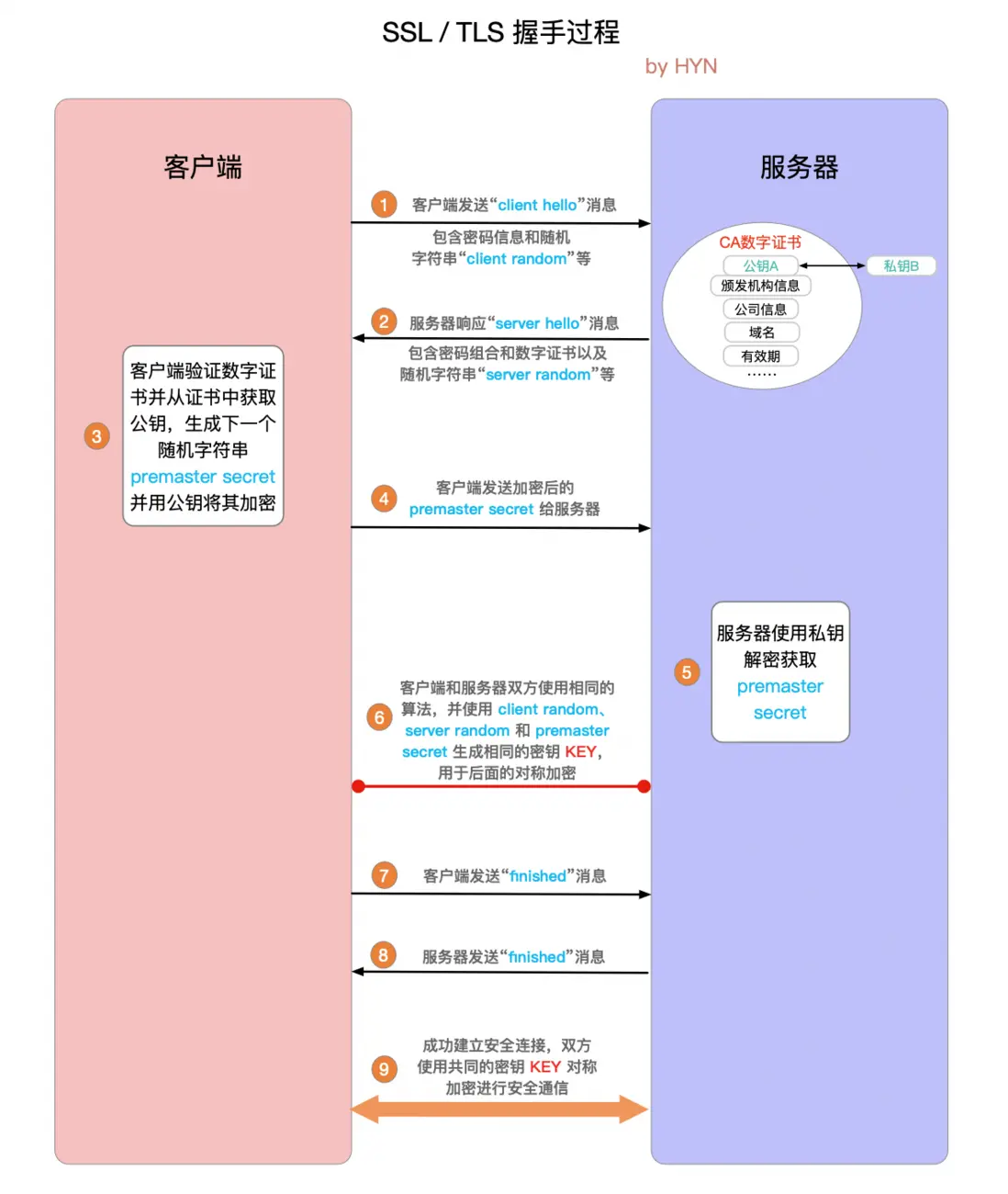
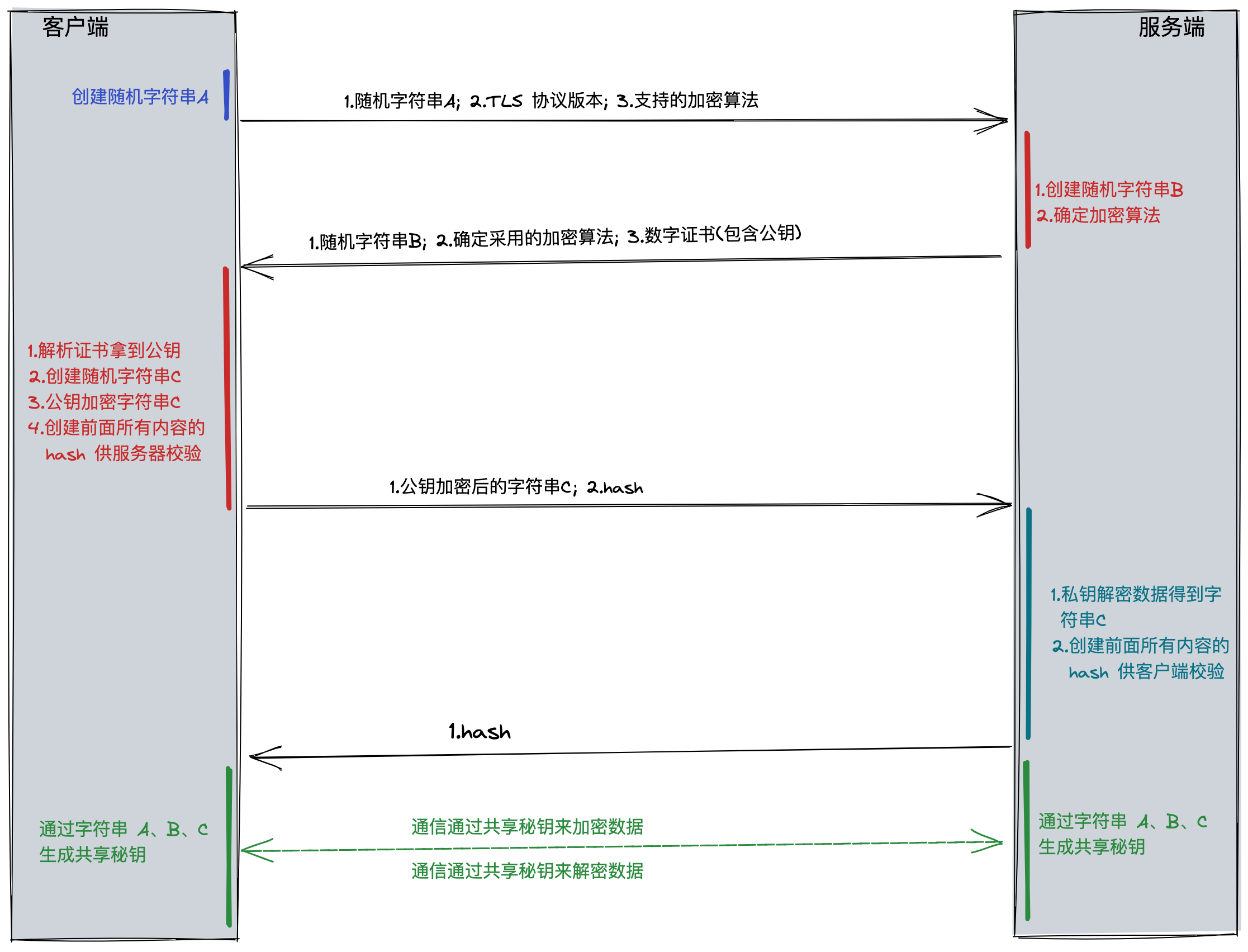
对于使用 HTTPS 建立的安全连接,还需要另四次 握手。这种握手,或者说 TLS 协商,决定使用哪种密码对通信进行加密,验证服务器,并在开始实际数据传输前建立安全连接。 如果使用的是 HTTPS 协议,在通信前还存在 TLS 的四次握手。
- "client hello"消息:客户端通过发送"client hello"消息向服务器发起握手请求,该消息包含了客户端所支持的 TLS 版本和密码组合以供服务器进行选择,还有一个"client random"随机字符串。
- "server hello"消息:服务器发送"server hello"消息对客户端进行回应,该消息包含了数字证书,服务器选择的密码组合和"server random"随机字符串。
- 验证:客户端对服务器发来的证书进行验证,确保对方的合法身份,验证过程可以细化为以下几个步骤:
- 检查数字签名
- 验证证书链
- 检查证书的有效期
- 检查证书的撤回状态
- "premaster secret"字符串:客户端向服务器发送另一个随机字符串"premaster secret (预主密钥)",这个字符串是经过服务器的公钥加密过的,只有对应的私钥才能解密。
- 使用私钥:服务器使用私钥解密"premaster secret"。
- 生成共享密钥:客户端和服务器均使用 client random,server random 和 premaster secret,并通过相同的算法生成相同的共享密钥 KEY。
- 客户端就绪:客户端发送经过共享密钥 KEY加密过的"finished"信号。
- 服务器就绪:服务器发送经过共享密钥 KEY加密过的"finished"信号。
- 达成安全通信:握手完成,双方使用对称加密进行安全通信。
全程采用的加密方式:
- 客户端使用非对称加密与服务器进行通信,实现身份的验证并协商对称加密使用的秘钥。
- 通过散列函数 hash 来校验数据完整性。
- 数据通信时采用对称加密,不同节点之间采用的对称秘钥不同,从而保证信息只能通信双方获取。 优点
- 使用 HTTPS 协议可以认证用户和服务器,确保数据发送到正确的客户端和服务器。
- 使用 HTTPS 协议可以进行加密传输、身份认证,通信更加安全,防止数据在传输过程中被窃取、修改,增加数据安全性。
- HTTPS 是目前最安全的解决方案,虽然不是绝对的安全,但是大幅增加了中间人攻击的成本。 缺点
- HTTPS 协议需要服务器和客户端双方的加密和解密处理,耗费资源更多、过程复杂。
- HTTPS 协议握手阶段比较费时,增加页面的加载时间。
- SSL 证书是收费的,功能越强大的证书费用越高。
- SSL 证书需要绑定 IP,不能在同一个 IP 上绑定多个域名。
为什么可以保证安全 基础概念
- 对称加密: 双方使用同一个秘钥进行加解密,对称加密虽然很简单性能也好,但是无法解决首次把秘钥发给对方的问题,很容易被黑客拦截秘钥。
- 非对称加密:用私钥加密的数据,只有对应的公钥才能解密,用公钥加密的数据,只有对应的私钥才能解密。因为通信双方的手里都有一套自己的秘钥对,通信之前双方会把自己的公钥都先发给对方。然后对方再拿着这个公钥来加密数据响应给对方,数据到了对方那里,对方再用自己的私钥进行解密
问题一 全部使用非对称加密虽然安全,但是速度慢,影响性能 解决方式:结合两种加密方式,将对称加密的秘钥通过非对称加密的公钥加密,然后发送出去,接收方使用公钥进行解密得到对称加密的秘钥,然后双方可以使用对称加密进行沟通。(非对称加密对称加密的密钥传输,然后后面都是用对称加密)
引入问题 中间人 如果此时在客户端和服务器之间存在一个中间人,这个中间人只需要把原本双方通信互发的公钥,换成自己的公钥,这样中间人就可以轻松解密通信双方发送的所有数据。 解决方式:这个时候需要一个安全的第三方颁发证书(CA)来证明身份,防止被中间人攻击,证书中包括: 签发者、证书用途、使用者公钥、使用者私钥、使用功能这的 hash 算法、证书到期时间等。
引入问题 中间人篡改了证书 如果中间人篡改了证书,那么身份证明不就无效了?这个证书就白买了。 解决方式:通过数字签名来解决这个问题,数字签名是用 CA 自带的 hash 算法对证书的内容进行 hash,得到一个摘要,再用 CA 的私钥加密,最终组成数字签名。当别人把它的证书发过来的时候,我再用同样的 hash 算法再次生成消息摘要,然后用 CA 的公钥对数字签名进行解密,得到 CA 创建的消息摘要,两者一比,就知道中间有没有被人篡改,这个时候就最大程度保证了通信的安全
HTTP 请求与响应
一旦我们建立了和 web 服务器的连接,浏览器就会代表用户发送一个初始的 HTTP ,请求报文由请求行、请求头、空行和请求体四个部分组成 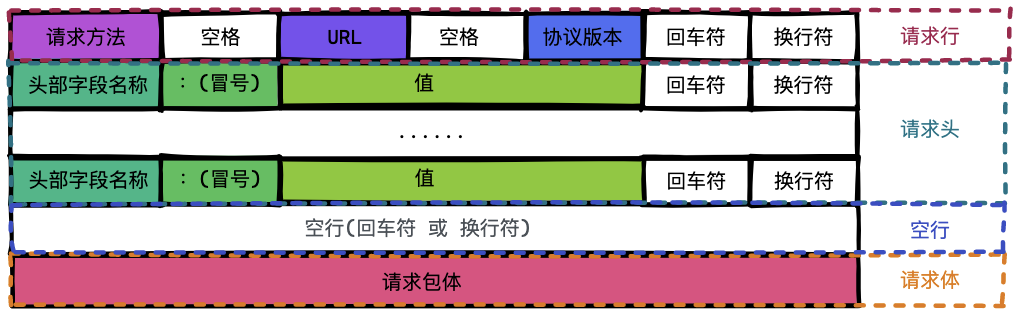
POST /getUser?id=ID HTTP/1.1
HOST: www.XXX.com
User-Agent: Mozilla/5.0(Windows NT 6.1;rv:15.0) Firefox/15.0
name=test&age=12请求行
请求行包含请求方法、URL 和版本协议。
请求头
请求头包含该请求的附加信息,由 key: value 组成,每个请求头独立成行。
请求体
请求体可以承载多个请求参数,但是并不是所有请求都会有请求体。
性能问题,拥塞控制 / TCP 慢启动
- 慢启动: 算法用于逐渐增加传输数据量,直到确定最大网络带宽,并在网络负载较高时减少传输数据量。
- 拥塞避免: 传输段的数量由拥塞窗口(CWND)的值控制,该值可初始化为 1、2、4 或 10 MSS(以太网协议中的 MSS 为 1500 字节)。该值是发送的字节数,客户端收到后必须发送 ACK。如果收到 ACK,那么 CWND 值将加倍,这样服务器下次就能发送更多的数据分段。相反,如果没有收到 ACK,那么 CWND 值将减半。因此,这种机制在发送过多分段和过少分段之间取得了平衡。
- 快速重传: ssthresh设置为cwnd的一半,cwnd设置为ssthresh的值,不需要重新进入慢启动阶段而是进入拥塞避免阶段
- 快速恢复
解析
一旦浏览器收到第一个数据分块,它就可以开始解析收到的信息。 当浏览器加载 HTML 并遇到标签时,它无法继续构建 DOM。它必须立即执行脚本。外部脚本也是如此:浏览器必须等待脚本下载,执行下载的脚本,然后才能处理页面的其余部分。
defer 和 async有一个共同点:下载此类脚本都不会阻止页面呈现(异步加载),区别在于:
async 执行与文档顺序无关,先加载哪个就先执行哪个;defer会按照文档中的顺序执行 async 脚本加载完成后立即执行,可以在DOM尚未完全下载完成就加载和执行;而defer脚本需要等到文档所有元素解析完成之后才执行 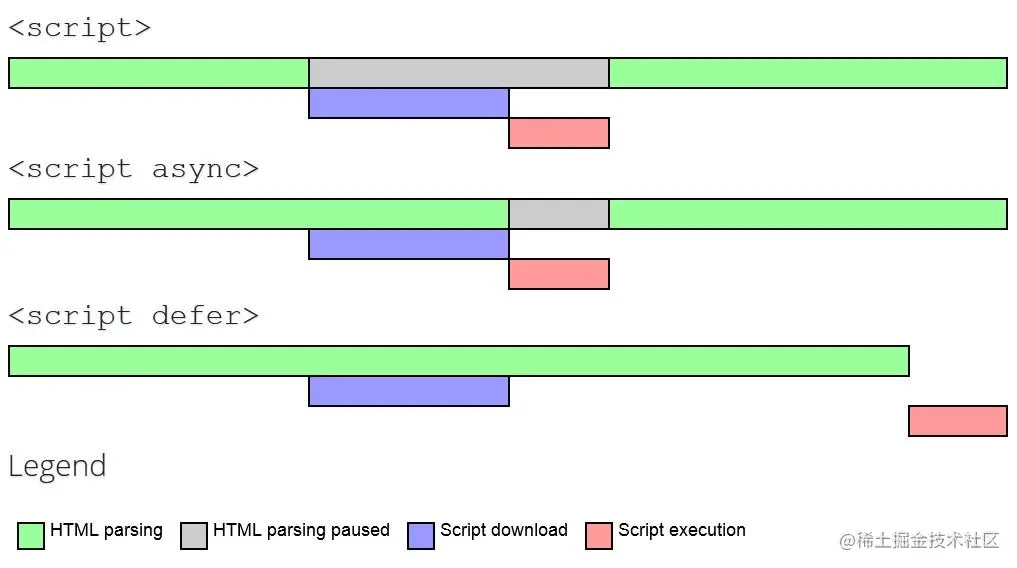
“解析”是浏览器将通过网络接收的数据转换为 DOM 和 CSSOM 的步骤,通过渲染器在屏幕上将它们绘制成页面。
构建DOM 浏览器会遵守一套步骤将HTML 文件转换为 DOM 树。宏观上,可以分为几个步骤: 
- 浏览器从磁盘或网络读取HTML的原始字节(字节数据),并根据文件的指定编码(例如 UTF-8)将它们转换成字符串。
- 在网络中传输的内容其实都是 0 和 1 这些字节数据。当浏览器接收到这些字节数据以后,它会将这些字节数据转换为字符串,也就是我们写的代码。
- 将字符串转换成Token,例如:
<html>、<body>等。Token中会标识出当前Token是“开始标签”或是“结束标签”或着是“文本”等信息。 - 构建DOM的过程中,不是等所有Token都转换完成后再去生成节点对象,而是一边生成Token一边消耗Token来生成节点对象。换句话说,每个Token被生成后,会立刻消耗这个Token创建出节点对象。注意:带有结束标签标识的Token不会创建节点对象。
接下来我们举个例子,假设有段HTML文本:
<html>
<head>
<title>Web page parsing</title>
</head>
<body>
<div>
<h1>Web page parsing</h1>
<p>This is an example Web page.</p>
</div>
</body>
</html>上面这段HTML会解析成这样: 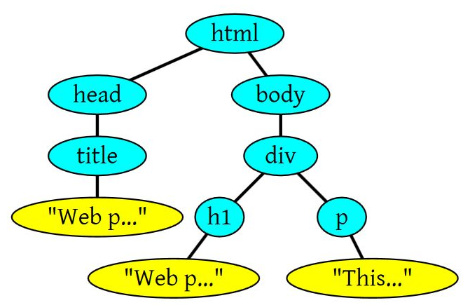
优化选项
- 请求页面的 HTML 大于初始的 14KB 数据包,浏览器也将根据其拥有的数据开始解析并尝试渲染。这就是为什么在前 14KB 中包含浏览器开始渲染页面所需的所有内容,或者至少包含页面模板(第一次渲染所需的 CSS 和 HTML)对于 web 性能优化来说是重要的。
- 当解析器发现非阻塞资源,例如一张图片,浏览器会请求这些资源并且继续解析。当遇到一个 CSS 文件时,解析也可以继续进行,但是对于
<script>标签(特别是没有 async 或者 defer 属性的)会阻塞渲染并停止 HTML 的解析。尽管浏览器的预加载扫描器加速了这个过程,但过多的脚本仍然是一个重要的瓶颈。
构建 CSSOM 树 DOM会捕获页面的内容,但浏览器还需要知道页面如何展示,所以需要构建CSSOM。构建CSSOM的过程与构建DOM的过程非常相似,当浏览器接收到一段CSS,浏览器首先要做的是识别出Token,然后构建节点并生成CSSOM。  浏览器在解析 HTML 时会遇到
浏览器在解析 HTML 时会遇到 <style> 标签或外部 CSS 文件的链接(<link>),它会继续下载并解析这些 CSS 文件。解析的结果是 CSSOM(CSS Object Model,CSS 对象模型)树,它描述了样式如何应用到 DOM 树中的元素。 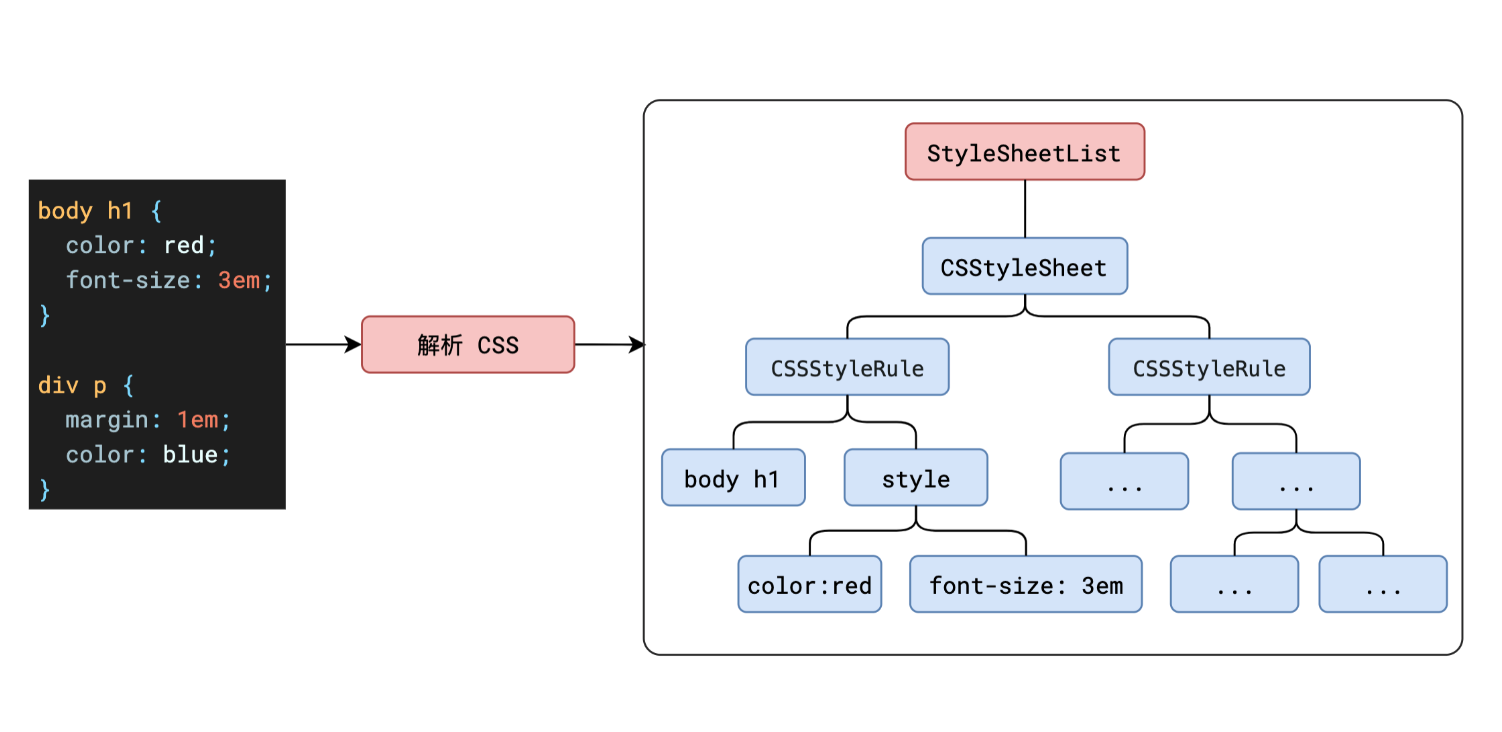
构建渲染树 浏览器将 DOM 树和 CSSOM 树合并,构建渲染树,在这一过程中,不是简单的将两者合并就行了。渲染树只会包括需要显示的节点和这些节点的样式信息。渲染树描述了页面上可见的元素以及它们的样式信息。需要注意的是,渲染树不包含 display: none 的元素,因为它们不会出现在页面中。
- 渲染树生成步骤:
- 从 DOM 树中选择可见元素(过滤掉
display: none的元素)。 - 根据 CSSOM 树为这些元素附加样式信息。
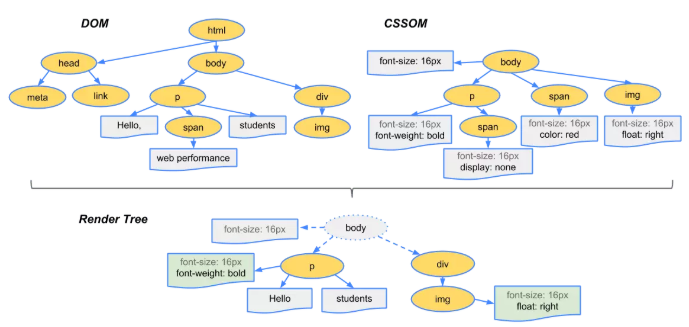
- 从 DOM 树中选择可见元素(过滤掉
其他过程
- 预加载扫描器 浏览器构建 DOM 树时,这个过程占用了主线程。同时,预加载扫描器会解析可用的内容并请求高优先级的资源,如 CSS、JavaScript 和 web 字体。多亏了预加载扫描器,我们不必等到解析器找到对外部资源的引用时才去请求。它将在后台检索资源,而当主 HTML 解析器解析到要请求的资源时,它们可能已经下载中了,或者已经被下载。预加载扫描器提供的优化减少了阻塞。 在这个例子中,当主线程在解析 HTML 和 CSS 时,预加载扫描器将找到脚本和图像,并开始下载它们。为了确保脚本不会阻塞进程,当 JavaScript 解析和执行顺序不重要时,可以添加 async 属性或 defer 属性。等待获取 CSS 不会阻塞 HTML 的解析或者下载,但是它确实会阻塞 JavaScript,因为 JavaScript 经常用于查询元素的 CSS 属性。
- JavaScript 编译 在解析 CSS 和创建 CSSOM 的同时,包括 JavaScript 文件在内的其他资源也在下载(这要归功于预加载扫描器)。JavaScript 会被解析、编译和解释。脚本被解析为抽象语法树。有些浏览器引擎会将抽象语法树输入编译器,输出字节码。这就是所谓的 JavaScript 编译。大部分代码都是在主线程上解释的,但也有例外,例如在 web worker 中运行的代码。
- 渲染互斥 渲染过程中,如果遇到
<script>就停止渲染,执行 JS 代码。因为浏览器有GUI渲染线程与JS引擎线程,为了防止渲染出现不可预期的结果,这两个线程是互斥的关系。JavaScript的加载、解析与执行会阻塞DOM的构建,也就是说,在构建DOM时,HTML解析器若遇到了JavaScript,那么它会暂停构建DOM,将控制权移交给JavaScript引擎,等JavaScript引擎运行完毕,浏览器再从中断的地方恢复DOM构建。
渲染
渲染步骤包括样式、布局、绘制,在某些情况下还包括合成。在解析步骤中创建的 CSSOM 树和 DOM 树组合成一个渲染树,然后用于计算每个可见元素的布局,然后将其绘制到屏幕上。在某些情况下,可以将内容提升到它们自己的层并进行合成,通过在 GPU 而不是 CPU 上绘制屏幕的一部分来提高性能,从而释放主线程。
样式 关键呈现路径的第三步是将 DOM 和 CSSOM 组合成渲染树。计算样式树或渲染树的构建从 DOM 树的根开始,遍历每个可见节点。
不会被显示的元素,如 <head> 元素及其子元素,以及任何带有 display: none 的节点,如用户代理样式表中的 script { display: none; },都不会包含在渲染树中,因为它们不会出现在渲染输出中。应用了 visibility: hidden 的节点会包含在渲染树中,因为它们会占用空间。由于我们没有给出任何指令来覆盖用户代理默认值,因此上述代码示例中的 script 节点不会包含在渲染树中。 每个可见节点都应用了 CSSOM 规则。渲染树包含所有可见节点的内容和计算样式,将所有相关样式与 DOM 树中的每个可见节点匹配起来,并根据 CSS 级联,确定每个节点的计算样式。
布局(Layout,或 Reflow)
渲染树构建完毕后,浏览器就开始布局。渲染树标识了哪些节点会显示(即使不可见)及其计算样式,但不标识每个节点的尺寸或位置。为了确定每个对象的确切大小和位置,浏览器会从渲染树的根开始遍历。 在网页上,大多数东西都是一个盒子。不同的设备和不同的桌面设置意味着无限数量的不同视区大小。在此阶段,根据视口大小,浏览器将确定屏幕上所有盒子的大小。以视口大小为基础,布局通常从 body 开始,设置所有 body 后代的大小,同时给不知道其尺寸的替换元素(例如图像)提供占位符空间,空间大小以相应元素盒模型的属性为准。 第一次确定每个节点的大小和位置称为布局。随后对节点大小和位置的重新计算称为重排。在我们的示例中,假设初始布局发生在返回图像之前。由于我们没有声明图像的尺寸,因此一旦知道图像的尺寸,就会出现重排。
- 布局的过程:
- 浏览器从渲染树的根节点开始计算,按照层次结构计算每个节点的几何信息(如
width、height、margin、padding、position等)。 - 浏览器会根据父子关系来计算子元素的位置和尺寸。
- 浏览器从渲染树的根节点开始计算,按照层次结构计算每个节点的几何信息(如
示例: 如果一个 div 设置了 width: 50%,浏览器会先计算父元素的宽度,再根据父元素的宽度计算该 div 的具体宽度。
绘制(Paint) 绘制涉及将元素的每个可见部分绘制到屏幕上,包括文本、颜色、边框、阴影以及按钮和图像等替换元素。浏览器需要以超快的速度执行这个过程。 为了确保平滑滚动和动画效果,包括计算样式、回流和绘制等占用主线程的所有操作,必须在不超过 16.67 毫秒的时间内完成。
绘制阶段: 在完成布局后,浏览器开始将每个节点绘制到屏幕上。浏览器会遍历渲染树,绘制每个节点的内容(文本、颜色、边框、阴影、图像等)。
绘制顺序:
- 先绘制背景颜色、背景图片。
- 再绘制边框、阴影。
- 最后绘制文本和内容。
分层与合成(Layering and Compositing)
- 分层(Layering): 浏览器会根据页面的复杂度,将一些渲染树中的节点分成多个图层。例如,具有
position: fixed或z-index的元素,可能会被分配到单独的图层中。 - 合成(Compositing): 不同的图层可能会被单独绘制,并由 GPU 进行合成操作,以减少重绘的开销。这样可以让某些图层的变化(如滚动、动画)只需重新合成而不必重新布局和绘制。
重排(Reflow)与重绘(Repaint)
- 重排(Reflow): 当页面的布局或元素的几何属性(如宽度、高度、位置等)发生变化时,浏览器会重新计算布局(即回流)。这可能会导致性能瓶颈,特别是在大量元素发生回流时。
- 重绘(Repaint): 当元素的外观发生变化但布局不变时(如颜色、背景图片等),浏览器会触发重绘,而不涉及布局的重新计算。相比回流,重绘的开销较小。
根据改变的范围和程度,渲染树中或大或小的部分需要重新计算,有些改变会触发整个页面的重排,比如,滚动条出现的时候或者修改了根节点。
- 何时发生回流重绘
- 页面一开始渲染的时候(这肯定避免不了)
- 浏览器的窗口尺寸变化(因为回流是根据视口的大小来计算元素的位置和大小的)
- 添加或删除可见的DOM元素
- 元素的位置发生变化
- 元素的尺寸发生变化(包括外边距、内边框、边框大小、高度和宽度等)
- 内容发生变化,比如文本变化或图片被另一个不同尺寸的图片所替代。
- 元素字体大小变化
- 激活CSS伪类(例如::hover)

8. JavaScript 执行对渲染的影响
- 阻塞渲染: 在页面解析过程中,JavaScript 文件可能会阻塞渲染。因为 JavaScript 可能会修改 DOM 或 CSSOM,浏览器必须等 JavaScript 执行完毕后,才能继续解析 HTML 并构建 DOM 和 CSSOM。因此,通常将 JavaScript 文件放在页面底部或使用
defer、async关键字来避免阻塞渲染。 - 操作 DOM: 当 JavaScript 操作 DOM(如
document.getElementById())时,可能会引发回流或重绘。因此,频繁的 DOM 操作可能会导致性能下降。应避免不必要的 DOM 操作或使用批量更新。
9. CSS 的影响
- 阻塞渲染: 与 JavaScript 类似,外部 CSS 文件也会阻塞渲染,因为浏览器需要先下载并解析 CSS,才能构建 CSSOM 树。未获取 CSS 文件时,浏览器无法渲染任何页面内容。
- CSS 优化: 为了提升页面性能,建议将 CSS 文件放在
<head>中,确保在 JavaScript 执行之前完成样式的解析。
总结:浏览器渲染流程的简要步骤
- 解析 HTML,构建 DOM 树:浏览器解析 HTML,生成 DOM 树结构。
- 解析 CSS,构建 CSSOM 树:浏览器解析 CSS 样式,生成 CSSOM 树。
- 构建渲染树:浏览器将 DOM 树和 CSSOM 树合并,生成渲染树,表示页面的可见元素和样式。
- 布局(Reflow):浏览器根据渲染树计算每个元素的大小和位置,完成布局。
- 绘制(Paint):浏览器遍历渲染树,将每个元素绘制到屏幕上。
- 分层与合成:浏览器根据页面的复杂性创建多个图层,最终由 GPU 合成这些图层,渲染页面。
通过理解浏览器的渲染流程,前端开发者可以采取相应的优化措施,如避免阻塞渲染的操作、减少 DOM 操作的次数、使用合适的图层分配等,从而提升页面性能和用户体验。
导致 Web 性能问题的原因
- 网络延迟
- 浏览器单线程执行